Chunking
# Using Context Chunking
Large Language Models operate over a limited token window, e.g., 4096 tokens. It is often impractical or impossible to fit large documents, web pages and video transcripts into a single GPT request.
Chunking is a technique that divides content of a web page or document into smaller parts, called chunks, ensuring each prompt fits within the GPT token limit. Chunks are injected into prompts as {{chunk}} parameter and processed by GPT one by one.
Chunking does not possess inherent memory. Therefore, if you require context to be maintained across chunks, it must be incorporated within the prompt.
Commands are easy to create and use. You do not need to have engineering knowledge to set up a custom AI command and boost your productivity.
# Step-by-step example
Once you have HARPA AI installed, follow these steps to create and reuse custom GPT commands with the Chunking option:
- To create a custom command, type / in HARPA AI chat and select the "Create command" option located at the top.
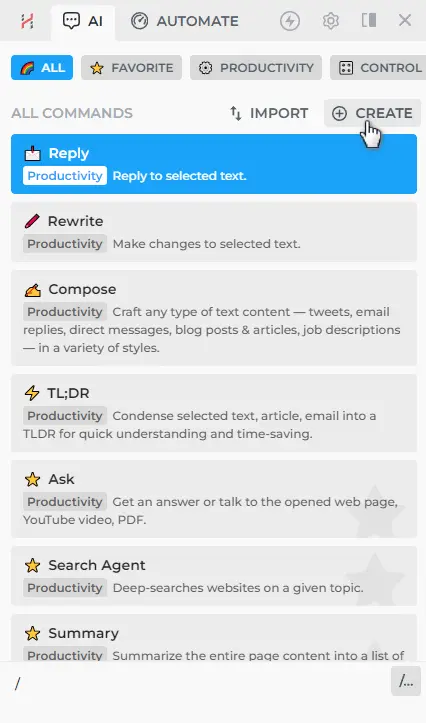
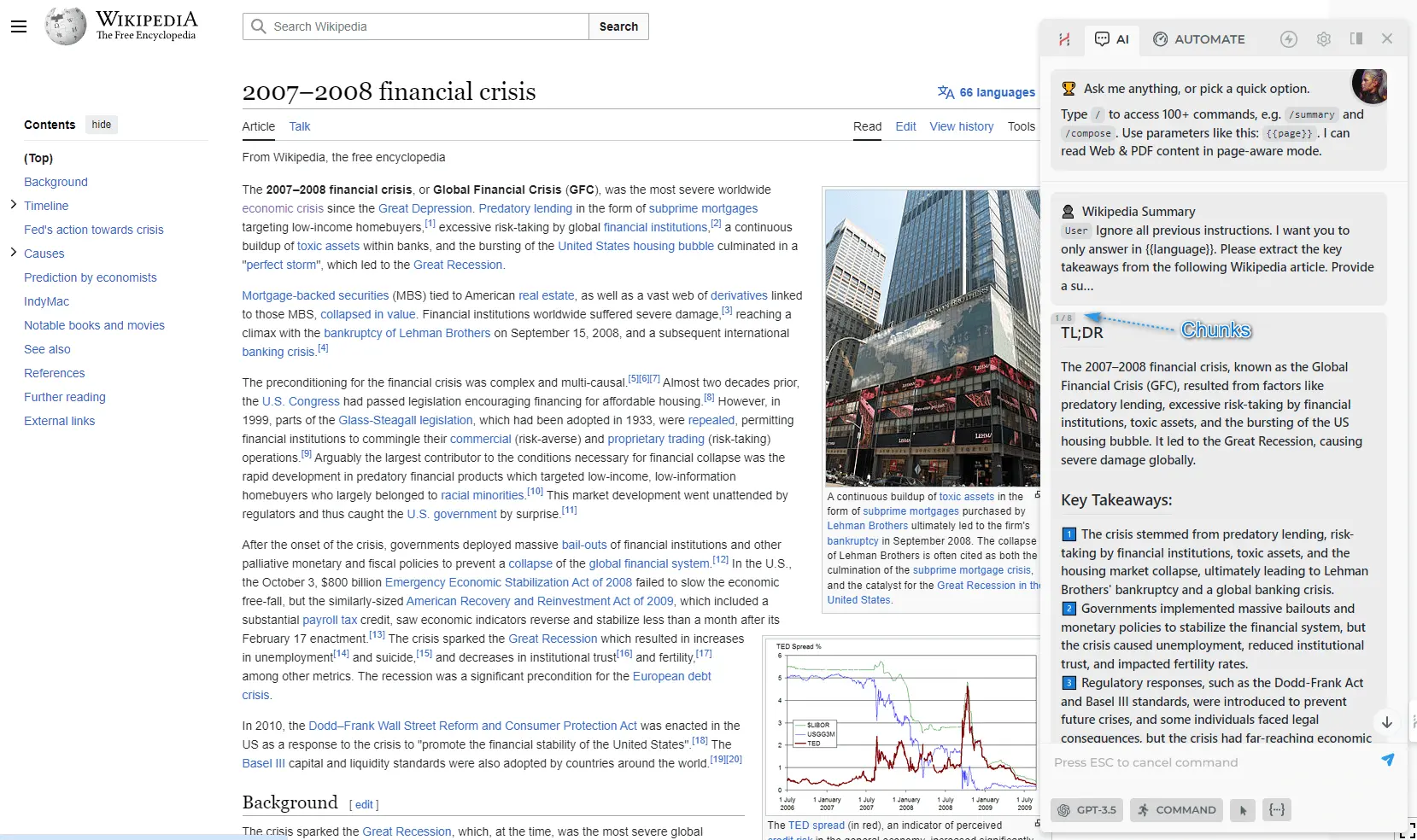
- Let's develop a custom command that creates a summary of a lengthy Wikipedia article, including a TL;DR section at the beginning. Add the GPT step:
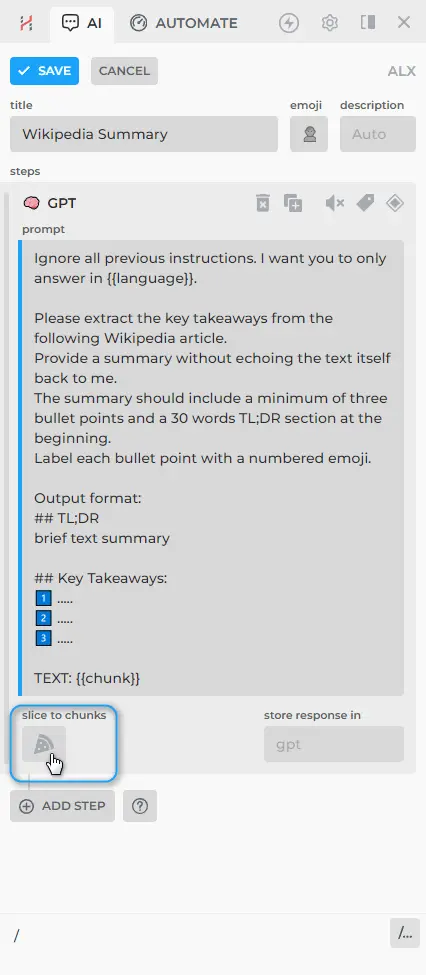
Here is the prompt text:
Ignore all previous instructions. I want you to only answer in {{language}}.
Please extract the key takeaways from the following Wikipedia article.
Provide a summary without echoing the text itself back to me.
The summary should include a minimum of three bullet points and a 30 words TL;DR section at the beginning.
Label each bullet point with a numbered emoji.
Output format:
## TL;DR
brief text summary
## Key Takeaways:
1️⃣ .....
2️⃣ .....
3️⃣ .....
TEXT: {{chunk}}
Notice how we used {{chunk}} parameter in our prompt to reference a part of the {{page}}.
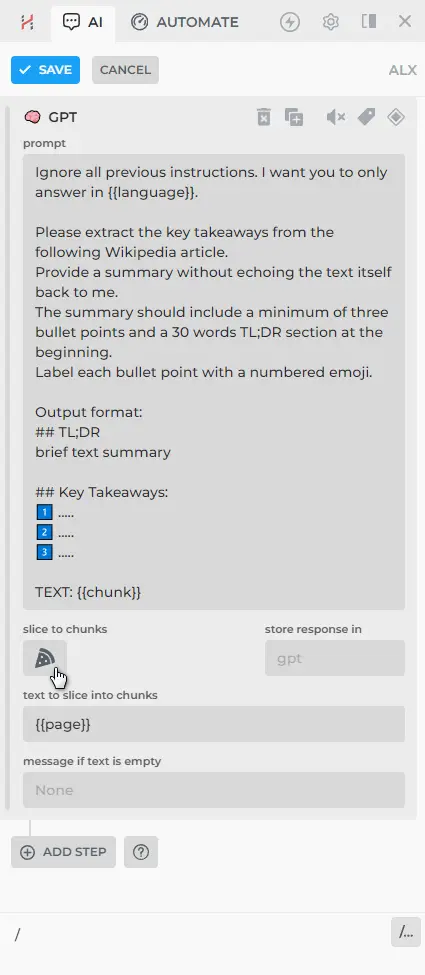
- Click "Slice to chunks" button (✂️ scissors icon) and select what text should be sliced. Let's put {{page}} since our command is designed to process the current webpage.
-
Once you have added the chunk prompt and selected the text to slice, click the 'SAVE' button to store your new command.
-
Your command will appear at the top, positioned above the pre-configured prompts, whenever you type the slash symbol /
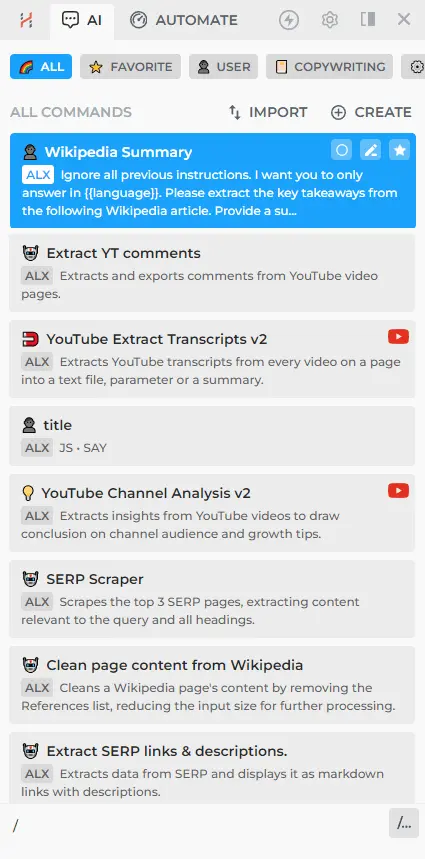
- Navigate to a Wiki webpage and try out your custom command.
-
HARPA AI combines (concatenates) GPT answers into a single parameter {{gpt}}. This way you can reference it in the following command steps. For example, you can condense the results of all segments into one summary.
-
Press the "Edit" button.
- Add the GPT step:
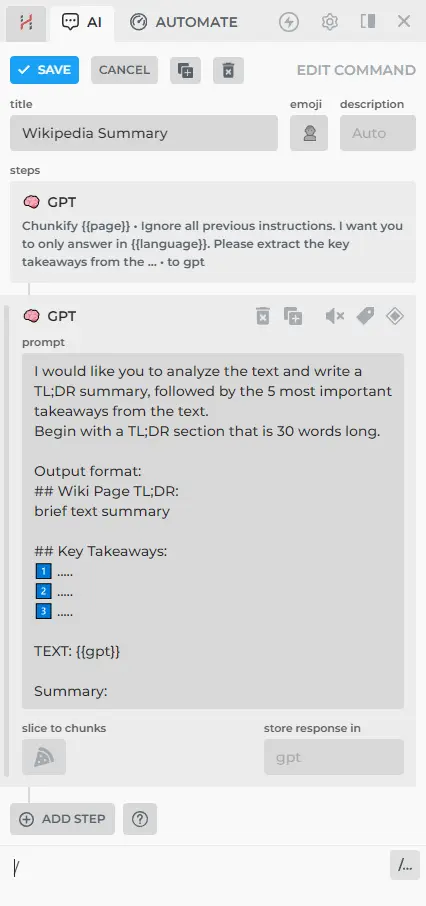
I would like you to analyze the text and write a TL;DR summary, followed by the 5 most important takeaways from the text.
Begin with a TL;DR section that is 30 words long.
Output format:
## Wiki Page TL;DR:
brief text summary
## Key Takeaways:
1️⃣ .....
2️⃣ .....
3️⃣ .....
TEXT: {{gpt}}
Summary:
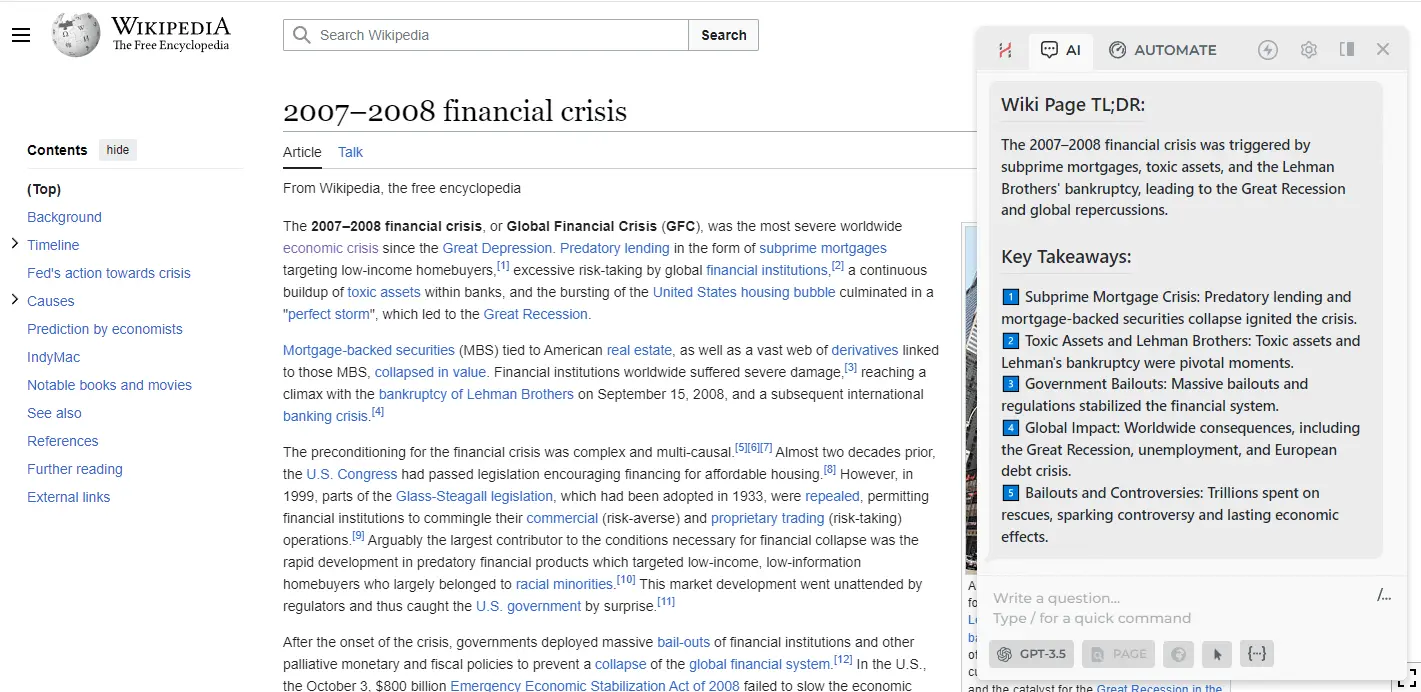
- Done! Now you have a ChatGPT command that dissects a large Wikipedia article into sections, summarizes them, and generates a concise summary that captures the main points from all segments.
# Alternatives to Chunking
You can use either {{page}} parameter as an alternative to chunking if you want to avoid running multiple GPT queries:
{{page}} parameter will return the entire web page or document as is, and fit as much of it into the prompt as possible for processing, cutting off the tail. This works best if your GPT model has a large context window e.g. gpt-3.5-turbo-16k.
# Use cases
With chunking, you have the ability to process huge web pages and documents sequentially.
This empowers you to effectively process and engage with large PDF documents, streamline your workflow and ensuring seamless handling of substantial textual content.
Moreover, if you're dealing with a lengthy book that requires analysis or summarization, chunking can be employed to divide it into more manageable sections that can be processed individually by the large language model.
# Links for further reading
All rights reserved © HARPA AI TECHNOLOGIES LLC, 2021 — 2026
Designed and engineered in Finland 🇫🇮
